CNN, from a novice view
Intro
第一次听说 CNN (Convolutional Neural Network) 是在上课的时候,见人用 CNN 做的服装图像检索,效果很不错。据说都是高分辨率图片,GPU 上跑了一周 = =,似乎很厉害的样子。终于现在我也要去尝试 Deep Learning 黑魔法了,于是把学到的总结一下,也算是为 blog 做开场白。
首先,让我们回到上世纪的 70,80 年代,那时候天还是蓝的,山还是绿的,SVM 还不知道在哪的时候,作为仿生学和人工智能的儿子的神经网络正在向前发展。生物、心理学上对于神经网络的研究,对人工智能领域神经网络的发展起到了一定推动作用。
neocognitron
而 neocognitron Fukushima 这个,就是受到生物学 Hubel 上的启发。其实在 neocognitron 之前,也有用来做视觉模式识别的神经网络,比如说 neocognitron 的爸爸 cognitron。不过这些网络大多都会受到输入的位移和形变严重影响,导致模式识别的能力并不是很强。而 neocognitron 可以根据几何相似性自主学习(representation & classification),而不会被位移或者小范围扭曲影响。
neocognitron 的结构如下:
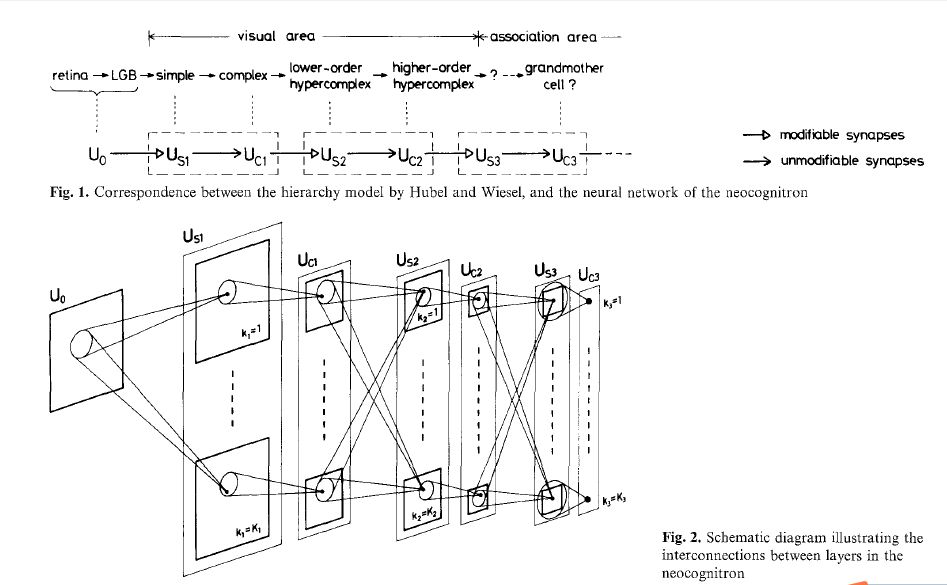
neocognitron 中有两种 cell,C-cell(complex) 和 S-cell(simple)。neocognitron 认为神经网络的每一个 module 都由一层 S-layer (由S-cell组成)和 C-layer (由C-cell组成)组成。$U_0$ 表示输入层,$U{C1}$,$U{S1}$ 等表示中间的 cell layer。
而在一个 layer 中,cell 被分成了小组,这样一组 cell 叫做一个 cell-plane (相似的,也有 S-plane 和 C-plane )。如图,一个 S-cell 和上一层 C-layer 中对应位置的一个区域中的 C-cell 相连,这个区域就是 S-cell 的 receptive field。也就是说,layer 之间的 cell 不是全相连的,cell 只和自己 receptive field 之内的 cell 连接。而同一 module 之中的 S-layer 和 C-layer 只是对应连接的,相邻 module 之间 S-layer 和 C-layer 是全相连的。而且,我们假设在一个 cell-plane 中的所有 cell 输入有着相同的 spatial distribution,也就是一个 cell-plane 中的所有 cell 用同样的 activation function,只是对应输入的位置不同。
cell-plane, receptive field 和这种连接方式是从分析实际生物视觉神经系统的来的,那他们对应的实际意义是什么呢?又有什么好处呢?实际上,cell-plane 就是一个 feature extractor,而 receptive field 可以说是 feature 的存在的范围。用一个具体的例子,我们要识别 “A” 这个字符,也就是识别下图中(a),(b),(c)三个 feature,如果他们空间上大致满足上,左下,右下的分布,那么输入就应该是一个 A。
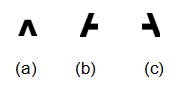
从 $U{S1}$ 来说吧,他直接接受输入,假设对于 $U{S1}$ 中的 $k{S11}$,$k{S12}$,$k{S13}$ 这三个 plane,分别识别 (a),(b),(c) 这三个 feature。$U{S1}$ 中每个 plane 都会接收全部 input,plane 中一个 cell 会接收其 receptive field 中的输入。而如果我们输入 A 的话,feature(a) 就会出现在 $k{S1}$ 中的一个 cell 的 receptive field,这个 cell 激发,传递到下一层。相似的,其他两个 feature 也会被相应 $k{S2}$,$k{S3}$ 中的 cell 检测到。$U{S2}$ (我们暂时忽略中间的 $U{C1}$)是跟上一级全相连的,也就是说 $U{S2}$ 的 $k{S21}$, $k{S22}$, $k{S23}$ plane 都接受了 $k{S11}$, $k{S12}$, $k{S13}$ 的输入。在这一级的 plane 中,假设$k{S21}$ 是当这三个形状分别在上,左下,右下时激发,此时恰好符合激发条件,$k{S21}$ 识别的就是 A。
这个 A 的例子是原文的缩写版,可以对应到原文的 $U{S2}$ 到 $U{S3}$ 部分:
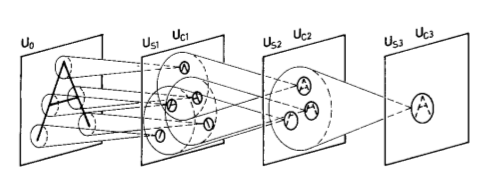
这样看起来似乎很奇妙的样子,但是又有很多问题。
首先,怎么知道 $k{S11}$ 会去感知 feature(a) 这个 feature 呢?做了这么多假设,plane 真的会学到这些 feature 么?当然这里只是个比方,根据实际的训练,可能 $k{S11}$ 探测的是 feature(b) 或者 feature(c),或者其他奇奇怪怪的也说不定。通过训练,神经元会学习根据数据学习到这些可以“明辨是非”的 feature,并且通过学习不断强化,使网络具备 pattern recognition 的能力。
S-plane 中所有 cell 的 receptive field 会覆盖之前一层的所有输出,也就是说他在全域上探测某一个 feature,而一个 cell 会探测其对应 receptive field,如果发现这个 receptive field 是它所“渴望” feature 的话,就会激发。而对应高阶的S-cell,则是如果发现他的 receptive field 是某些 feature 的组合时,才会激发。同一个 plane 中相邻的 cell 的 receptive field 是 overlap 的。比如说 cell 的 receptive field 是 5x5,因为他们之间相邻,就会有 5x4 的重合区域。这样就保证了 feature 在存在位移时一样可以被其他 cell 探测到,输出到下一层。有一个附带的问题是,既然一个 plane 是检测一个 feature,plane 数目是预先设定的,feature 数是未知的,feature 数目完全可能比 plane 多啊。实际上,通过训练,plane 识别的 feature 并不是单一的,很可能是我们直观上几种 feature 的组合,而网络总会去学习适应训练的结果。
位移的问题解决了,但是如果输入存在扭曲变形呢?这就是刚刚被我们忽略的 C-cell 的作用。在一个 module 中,C-cell 起到了 subsampling 的作用。再举一个例子,一个 module 中的 S-plane 和 C-plane 的大小分别是 6x6 和 3x3,那么对于一个 C-cell 来说,他的 receptive field 就是 S-plane 中对应的 2x2 的区域,C-cell 会把 receptive field 中的信息做 average。也就是说,随着 layer 层次越深,精确的位置信息被淡化,只会保留大致的相对位置信息。
拿 feature(a) 来说,写 A 的人可能会往左偏或者往右偏导致扭曲。对于上面的 6x6 到 3x3 的 subsampling 来说,只要 receptive field 中 2x2 的average 达到使 cell 激发的水平(当然,这里的 average 是要加 weight 和 bias 的,还是看训练),就可以说明这个 feature 存在,换句话说,通过 subsampling,feature(a) 可以在左右 2 个 pixel 之内的扭动我们都可以识别。而对于 high-order 的 feature,subsampling 的力度更大,允许扭曲的程度也就越大。不过正如刚刚括号里面说的,这取决于训练,比如说,如果你的训练数据都是方方正正公正的(=_=b)的 A,那么训练的容错性是不会好的,而如果训练数据有各种倾斜的 A,那么通过训练,subsampling 上的 weight 和 bias 就会被不断调节,来增强容错。从这里可以看出来,神经网络的训练是需要大数据集来保证的,数据量不够很容易 underfit。
neogconitron 实际上已经是 CNN 了,上面唯一缺少的就是 convolution 的引入。
CNN
在 LeCun89 中,cell-plane 中的所有 cell 输入有着相同的 spatial distribution 的思想被提炼为 weight sharing。weight sharing 一方面符合特征提取的要求(在输入全域上提取某种相同特征),另一方面极大的减少了 free parameter(一个 plane 中的 cell share 相同的 parameter)。另外,S-plane 被起了个新名字,feature map。上一级的输入会被映射到不同的 feature map 组合成高阶 feature,继续进行识别。当然,重要的不是新名字,重要的是 weight sharing 和 feature map 被抽象成 convolution。假设一个 feature map 中的 receptive field 是5x5,根据 weight sharing,这个 feature map 在 input 的全域上每个 5x5 的区域内都在做相同的 operation,每个 cell output 从之前 5x5 的 receptive field 得到,那得到 feature map output 不就是一个对上层 feature map 做 5x5 kernel 的 convolution 么,而 kernel 正是 cell weight。从另一个角度来看,train 这个 CNN 实际上是一个学习 kernel 的过程,试图让 kernel 的滤波效果更好~
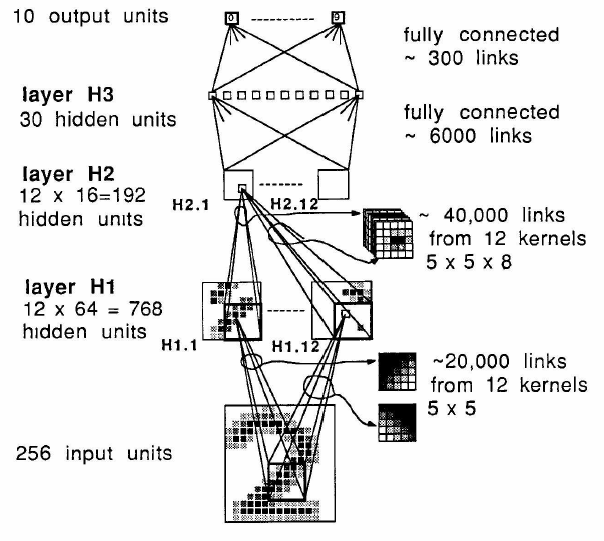
跟 neogonitrion 有一点不大一样的是:1、这里的CNN没有 subsampling layer(C-layer),而是直接在卷积时做 subsampling;2、在网络的最后,用了两层全相连层,最后有 10 个输出,对应 10 个数字,而在 neogonitron 没有用全相连层,,最后是 24 个输出,训练时则随机选择一个 output cell 作为对应数字的 label cell。实际上,这两种方法都有一定问题, LeCun98 中有详尽描述,并且提出了改进后的 CNN —— LeNet-5,留着下次接着写好了~
码字好累= = 先写这么多~
Reference:
#### Hubel, D. H., & Wiesel, T. N. (1962). Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. The Journal of physiology,160(1), 106. #### Fukushima, K. (1980). Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological cybernetics, 36(4), 193-202. #### LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., & Jackel, L. D. (1989). Backpropagation applied to handwritten zip code recognition. Neural computation, 1(4), 541-551. #### LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324.
> 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 <