CNN, from a novice view (II)
LeNet-5
上篇 blog 的结尾有说到 neogonitron 和后来 LeCun89 的 CNN 都存在一定问题。他们都用某一个 output cell 的输出作为某一个 class 的 likelihood。也就是说,对于一个训练好的网络,输入一个图片,最后 output layer 中的 cell 谁的输出大,那么这个图片就会被认为是这个 cell 的 label。
-
就拿手写的 l,1,O, 0,o 来说,如果没有上下文语义的帮助,无论人和计算机都很难搞定。一方面是很难训练;另一方面这样输出只是字符,很难结合语义分析。试想,如果我们的 cell 是在“输入是一个圈”时激发,那么我们接下来就可以根据语义继续判断是 uppercase O,lowercase O 或者零了。
-
对于 sigmoid unit 来说,采用这种近乎 uniform distribution 的 label 分布在 cell 上方法表现很差,特别是类多的时候。这是因为我们总是期望只有一个 cell 激发,其他全部 off。
-
除了 accept character 之外,对于 reject non-character 来说,sigmoid 的表现并不够好。
下面是盗图自 wikipedia 的 sigmoid function。

LeNet-5 利用 Euclidean Radial Basis Function units (RBF) 组成 output layer 来避免这三个问题(其实这里是倒叙啦,原文是因为这三个原因所以采用 RBF =_=b)。
对于 RBF unit $y_i$ ,输出根据下式计算:
也就是说每一个 RBF 都在计算输入和他参数 $_{ij}$ 的欧式距离。输出越大,距离越远,也就是越不可能属于这个类(negative likelihood)。而对于每个 unit,参数是人工选择的(至少起始是要人肉去做)。参数如下图:

哈,这样一看就明白了吧。实际上网络就是起到了滤波和标准化的作用,最后跟 char set 一匹配,就知道谁是谁了!
而这个参数($w_{ij}$)都是 $+1$ 或者 $-1$。$+1$ 和 $-1$ 恰好是 sigmoid 的两个极值,这从一定程度上避免了 sigmoid 的饱和(saturation)。
一直在说 LeNet-5,都忘记来张 LeNet-5 的全景了。。。
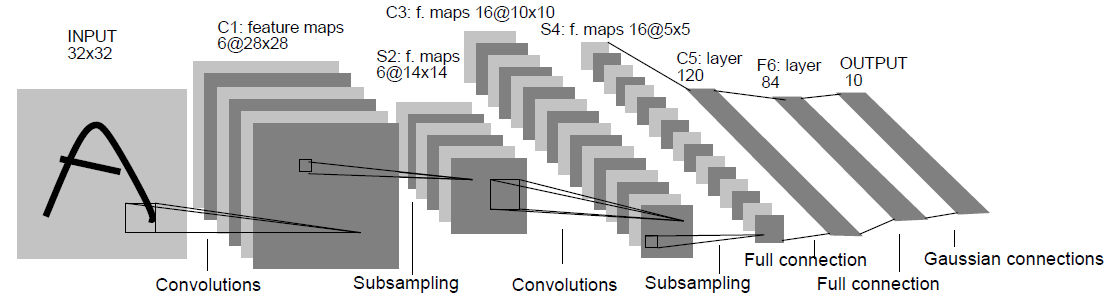
F6 和 output 之间的 connection 就是上面所说的 RBF 的关系~
除了 RBF 的应用,LeNet-5 还有什么亮点呢。下图是 S2 中的 feature map 和 C3$ 中 feature map 的连接方式。
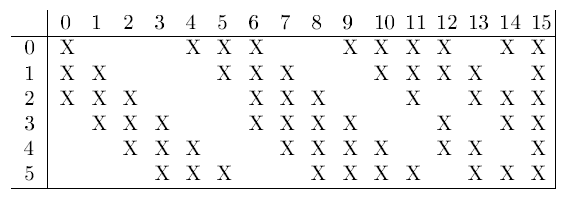
在这里,module 之间的 feature map 不在是全相连,而是有选择的相连。C3 的 feature maps 在这里分别是前六个连接 S2 连续 3 个 feature map,后六个连续 4 个 S2 feature map,之后是一些非连续 4 个 feature map 相连,最后一个和所有 feature map 相连。
不采用全相连基于两个理由:
-
非完全相连保证连接数量在一个合理的范围内,不会为训练增加过多负担。
-
保证网络是非对称的,不同 feature map 可以提取不同的特征。
在 CNN 方面,LeCun89 还在 neural network unit 上的参数选择做了工作,当然对于理解 CNN 来说可以暂时略过。这篇 paper 提出了用来自动分割和识别词或者字符串的 Graph Transformer Network (GTN) ,CNN 是其中的一个 component(当然这也不是我们关注的重点)。重点是,LeNet 在 paper 中的实验结果完爆了其他各种方法,这就是强大的神经网络。
好吧刚才我说的是 LeNet 而没有特指 LeNet-5,这是因为 LeNet-4 的一个变种, Boosted LeNet-4, 要比 LeNet-5 的实验结果 error rate 小了千分之一。LeNet-4 其实是中间 layer 更多,output 没有 RBF 只是 10 个对应 label 的 cell(差点忘了说 test data set 是 MNIST,所以是 10 个数字嘛)。
首先来简单解释一下 Boosting Algorithm。简单来说,就是三个臭皮匠,顶上一个诸葛亮。组合几个很 weak 的算法(learner),可以得到更好的结果 Schapire。
Boosted LeNet-4 由 3 个 LeNet-4 组成。第一个按常规方法训练。第二个用第一个网络的过滤后的 pattern 训练,其中 50% 用第一个网络搞错的,50% 用第一个网络结果正确的。第三个网络用第一和第二个网络 disagree 的 pattern 训练。最后输出就是三个网络输出的叠加。就是这三个臭皮匠的结果,比 LeNet-5 好了千分之一。而 raw LeNet-4 要比 LeNet-5 差千分之三。
Max pooling
其实,在上篇 blog 中,为了理解方便我说 neocognitron 的 cell 在接受多个输入时是取 average 的,实际上 neocognitron 是取 input 中的 max。这也是受生物上启发的 Hubel 。不过后来大家都开始用 $\sigma$ 这货来做(取和,也就是 average)。然而, max pooling 并没有沉默。
首先用 “pool” 这个词的似乎是 Serre,pool 就是表示对一个“池子” 一坨 的 input 做一个操作,使其变成变成一个量。Serre 描述的也是一个 network 型的识别方法,不过跟 CNN 不同的是,它没有放任自由的训练,综合了一些视觉中的方法(Gabol filter, SIFT-feature)作为中间的 layer 来提取特征。不过悲催的是这样的效果并没有 bench 上的飞跃。不过 max pooling 的精神长存。
经过 Scherer、Boureau,max pooling 被验证是一种有效的方法,CNN 中的 subsampling layer 也就渐渐的进化成了 max pooling layer。至此,当代 CNN 的 architecture 已经基本形成。在 ImageNet Krizhevsky 中,CNN 更是完爆了所有 the state of art 方法,展现了 deep neural network 的强大威力。
至于 Krizhevsky 到底有多厉害diao,留着下次继续表好了~~ EOF XD
Reference:
#### LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., & Jackel, L. D. (1989). Backpropagation applied to handwritten zip code recognition. Neural computation, 1(4), 541-551. #### LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324. #### Schapire, R. E. (1990). The strength of weak learnability. Machine learning, 5(2), 197-227. #### Hubel, D. H., & Wiesel, T. N. (1962). Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. The Journal of physiology,160(1), 106. #### Serre, T., Wolf, L., & Poggio, T. (2005, June). Object recognition with features inspired by visual cortex. In Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on (Vol. 2, pp. 994-1000). IEEE. #### Scherer, D., Müller, A., & Behnke, S. (2010). Evaluation of pooling operations in convolutional architectures for object recognition. In Artificial Neural Networks–ICANN 2010 (pp. 92-101). Springer Berlin Heidelberg. #### Boureau, Y. L., Ponce, J., & LeCun, Y. (2010). A theoretical analysis of feature pooling in visual recognition. In Proceedings of the 27th International Conference on Machine Learning (ICML-10) (pp. 111-118). #### Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. In NIPS (Vol. 1, No. 2, p. 4).
> 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 <